

Current processes violate GDPR
Out of the six data protection principles, translation regularly violates at least four: purpose limitation, data minimization, storage limitation, and confidentiality. This last one is most likely mentioned in most purchase orders, but it is hard to live up to in an industry which squeezes out every last cent in a long supply chain.
Spicier is the fact that translators don’t need to know any personal data to translate a text, like who made the payment and how much money was transferred, as in the sample below. Anonymized source texts would address purpose limitation and data minimization. The biggest offenders, however, are the industry’s workhorses: neural machine translation (NMT) and translation memory (TM). NMT trains and TM stores texts full of personal data without means of deleting it, even though it was unnecessary for them to store the protected data in the first place.
A GDPR-compliant translation workflow
Some might argue that this difficult problem cannot be fixed. Well, it can. And not only this, our anonymization workflow saves money and increases quality and process safety, too.
On a secure server ‘named entities’ (i.e. likely protected data) are recognized. This step is called NER, a standard discipline of Natural Language Processing. There are several anonymizers on the market, mainly supporting structured data and English, but they only support a one-way process.
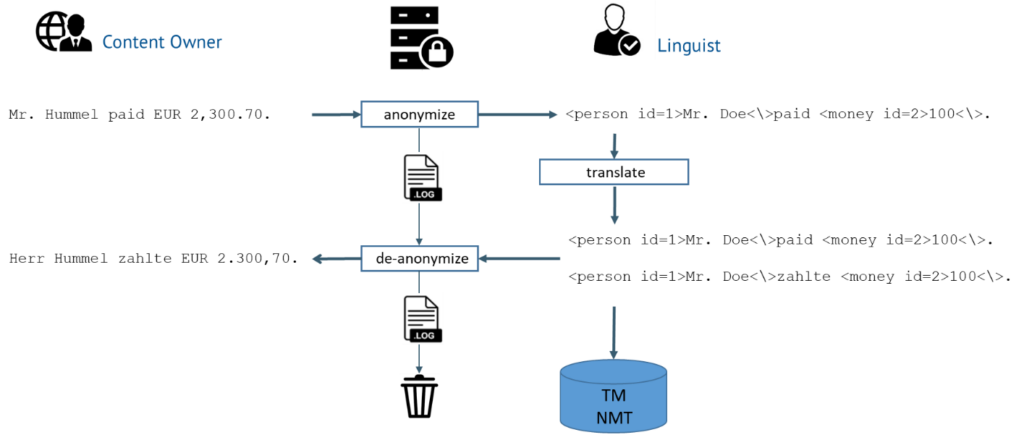
In our solution, the data is actually “pseudonymized” in both the source and target languages. This keeps the anonymized data readable for linguists by replacing protected data with another string of the same type. Once translated, the text is de-anonymized by replacing the pseudonyms with the original data. This step is tricky since the data also needs to be localized, as in our example with the title and the decimal and thousands separators. The TMs used along the supply chain will only store the anonymized data. Likewise, NMT is not trained with any personal data.
Know-how
We recently did a feasibility study to test this approach. Academia considers NER a solved problem, but in reality it’s only somewhat done for English. Luckily, language models can now be trained to work cross-language. Rule-based approaches, like regular expressions, add deterministic process safety. For our study we extended the current standard formats for translation, TMX and XLIFF, to support pseudonymization. De-anonymization is hard, but I had already previously developed its basics for the first versions of TRADOS.
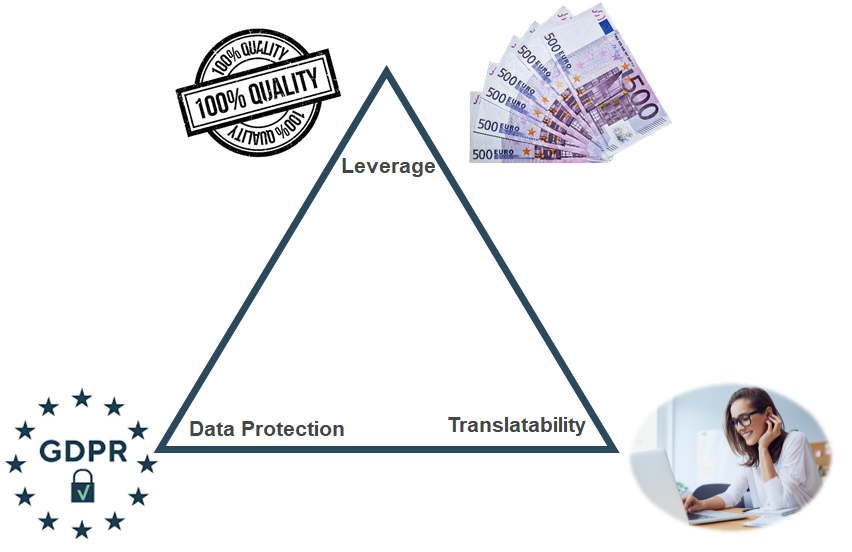
What remains is the trade-off between data protection and translatability. The more text is anonymized, the better the leverage – but the harder the text is to understand for humans, too. Getting that balance right will still require some testing, best practices, and good UI design. For example, project managers will want a finer granularity on named entities than normally provided by NER tools. Using a multilingual knowledge system like Coreon, they could specify that all entities of type Committee are to be pseudonymized, but not entities of type Treaty.
Anonymization is mandatory
As shown above, a GDPR-compliant translation workflow is possible, and is thus legally mandatory. This is, in fact, good news. Regulations are often perceived as making life harder for businesses, but GDPR has actually created a sector in which the EU is a world leader. Our workflow enables highly-regulated industries, such as Life Sciences or Finance, to safely outsource translation. Service providers won’t have to sweat over confidentiality breaches. The workflow will increase quality as named entities are processed by machines in a secure and consistent way and machine translation has fewer possibilities to make stupid mistakes. It will also save a lot of money, since translation memories will deliver a much higher leverage.
If you want to know more, please contact us.


