

Together with partners, Coreon is a part of CEFAT4Cities Action, a project co-financed by the Connecting Europe Facility of the European Union. It targets the interaction of EU residents and businesses with public services. Two of its outcomes are an open multilingual linked data repository and a pilot chatbot project for the Vienna Business Agency, which leverages the created resource.
A Chatbot, But Make It Smart
If you’ve ever scratched the surface of conversational AI development, you know that there are innumerable ways to develop a chatbot.
In this post, we’ll talk about technical challenges and solutions we’ve come up with when developing a multilingual chatbot for our partner, the Vienna Business Agency (VBA), in scope of the CEFAT4Cities project.
On a high level, the CEFAT4Cities initiative aims to speed up the development and adoption of multilingual cross-border eGovernment services, converting natural-language administrative procedures into machine-readable data and integrating them into a variety of software solutions.
The goal of SmartBot, in turn, is to make VBA’s services discoverable in a user-friendly and interactive way. The services include assistance with starting a business, finding relevant counseling, or drawing up a short list of grants from dozens of available funding opportunities for companies of various scale.
Summary
We share our bot-building experience, demonstrating how to overcome the language gap of local public services on a European scale and reduce red tape for citizens and businesses.
Our solution is driven by multilingual AI and leverages a language-agnostic knowledge graph in the Coreon Multilingual Knowledge System (MKS). The graph contains VBA-specific domain knowledge, an integrated ISA2 interoperability layer, and vocabulary-shaped results of the CEFAT4Cities workflows.
This blogpost covers the following aspects:
- Rasa, SmartBot’s Skeleton
- The Quest of Domain Knowledge
- Drafting Domain Knowledge
- Going Multilingual
- Relations for Semantic Search
- Homonymy and Terms Unseen by Model
- Conclusion
Rasa, SmartBot’s Skeleton
SmartBot’s natural language understanding component (NLU) and dialogue management are powered by Rasa Open Source, a framework for building conversational AI.
Of course, there is a wide variety of frameworks for building chatbots out there. We’ve chosen Rasa because it’s adjustable, modular, open source, and ticks all boxes with our feature requirements. It can be run in containers and hosted anywhere, providing most popular built-in connectors as well as letting you build the custom ones. Rasa’s blog offers a variety of tutorials, and there is an active community of fellow developers at the Rasa Community Forum.
However, there is a catch: expect to work up some sweat when setting things up, and maybe look somewhere else if your engineering resources are scarce or you’d rather go for an easier no-code solution that can be supported by a less ‘tech-y’ part of the team.
But back to Rasa. To briefly summarize the main points (for the architecture components see https://rasa.com/docs/rasa/img/architecture.png ): Rasa NLU handles intent classification (aka “what the user is implying”) and entity identification in a user’s input; Dialogue management predicts a next action in a conversation based on the context. These actions can be simple responses, serving strings of text/links/pics/buttons to the user, as well as custom actions containing arbitrary functions.
In SmartBot’s case, we also heavily rely on Rasa SDK — it handles all our custom code organized as custom actions (e.g., search a database, make an API call, trigger a handover of the conversation to a human, etc).
The Quest Of Domain Knowledge
In a nutshell, the MKS is a semantic knowledge repository, comprised of concepts linked via relations.
So, let’s add knowledge graphs to this chatbot business. By now you probably have a feeling that a big chunk of implementation work is associated with domain knowledge. The challenge here is that proprietary domain experts and NLP engineers are rarely the same people, so coming up with a process that ensures a smooth cooperation in knowledge transfer can save a lot of time and hassle.
That’s why our architecture features an integration with the Coreon MKS that allows domain experts to easily and intuitively draft their domain knowledge as a graph.
In a nutshell, the MKS is a semantic knowledge repository, comprised of concepts linked via relations. It caters for discovery, access, drafting, and re-usability of any assets, organized in language-agnostic knowledge graphs.
Since linking is performed at the concept level, we can abstract from language-specific terms and model structured knowledge for phenomena that reflect the non-deterministic nature of the human language (e.g., word sense ambiguity, synonymy, homonymy, multilingualism).
This linking ‘per concept’ also ensures smooth maintenance of relations without additional data clutter and helps us exchange information among acting systems so that precise meaning is understood and preserved among all parties, in any language.
If this still sounds like more work rather than a challenge-overcoming solution, please carry on reading. We’ll now go through concrete cases where we scored multiple points relying on Coreon’s functionality.

Drafting Domain Knowledge
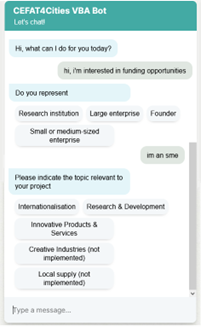
We asked the Vienna Business Agency to draft their knowledge graph and, based on their graph input, we sketched core entities and identified intents that must be recognized in user queries by SmartBot.
In this screenshot you see how VBA’s domain knowledge is represented and curated in Coreon, and how it is reflected in the chatbot’s UI.
In essence, to determine relevant business grants, SmartBot guides the user through a series of questions, narrowing down the selection to most suitable funding programs and fetching back all applicable grant records. While traversing trees of questions, we collect relevant information from the user and further search the VBA grant database or make API calls to Coreon if the NLU model gets confused.
Aside from the VBA domain knowledge, we also use the MKS to curate the interoperability layer and public service multilingual vocabularies, the result of applying the CEFAT4Cities workflows.

Going Multilingual
We see multilinguality as one of our biggest assets, but this feature also comprises a big conceptual challenge: it is very important to have a very clear idea about the kind of multilinguality you want to serve because most likely it will fully shape or at least heavily influence the architecture and scalability of the final solution.
Do you need the chatbot to detect the language of the user’s message and carry on the conversation in the detected language? Or would you prefer the user selects the language manually in the UI, from the limited language options on offer? Should the bot ‘understand’ all languages but reply only in one? Or reply in the one specified by the user? Or maybe reply in the detected language of the last message? Are you working on the solution for an audience that tends to mix/speak several languages?
Serving the same info in different languages?
- Language detection vs manual selection in UI
- Should Bot ‘understand’ all languages but reply in one?
- Or rather reply in the language of the last message?
While sticking all languages in one chatbot deployment appears to save resources, most likely you’d have to deal with a lot of mess in the data and potential confusion among languages. That hardly sounds like a sustainable and a robust option.
We decided to go with individual NLU models per language, i.e. keeping them language-specific, while making dialogue management/Stories universal for them all, adding an additional layer of abstraction to maintain consistency in the bot’s behavior.
Our approach
- NLU models per language
- One universal Core model/Stories
With all its beauty, this approach brings another challenge along: the core model, responsible for dialogue management. It shouldn’t have a single language-specific string among the training data, so we need to find an abstraction for the representation of entities, aka keywords of variety of types, found in the user’s input.
Challenge:
- Stories contain entities, aka language-specific keywords
- thus, should be mapped to some language-independent IDs
Luckily, we don’t have to look any further.
On this screenshot you see the output from EN NLU model, given the sample input, “hi, I’m interested in subsidies”.

You get the recognized intent of this message, want_funding, and below that are the entity type, funding, and the value, the string subsidies.
While NLU digests the user’s input and neatly extracts entities recognizing their types, entity records in the domain knowledge of the VBA are being constantly updated, which needs to be addressed by the bot. We therefore abstract from entity maintenance in distinct languages and replace language-specific terms with their unique Coreon concept IDs, resulting in the output below:

Again, we do it because maintaining entities in each language separately would be tedious and not consistent, particularly since the VBA domain knowledge is not static. Also, agnostic entities are crucial for keeping the Rasa Core module language-agnostic, abstracted from entity names in a specific language.
Once VBA decides to expand SmartBot’s language capabilities with a new language, ‘universal entities’ will ensure a smooth model development and minimization of the labeling effort – as the entities are already there.
Relations For Semantic Search
A few words about another handy feature that is brought into this project by the mighty knowledge graph.
By now it is clear that SmartBot serves the user relevant grant recommendations based on the input they provide. Of course, it implies that at some point the bot will query some data source that contains records on VBA grants and other funding opportunities.
To retrieve appropriate records, we need to match all information that influences the funding outcome. Since SmartBot gives users freedom of free text input queries and not just fixed button-clicking, solely using keyword extraction and further string matching would not help fetch any relevant records from the database.
This is where we can leverage relations between concepts stored in Coreon. For example, in their query the user may use a term that is synonymous or closely related to the one accepted by the VBA database.
When asked what kind of company they represent, the user inputs ‘Einzelkaufmann‘, German for ‘registered merchant’. This entry doesn’t show up in the database, and computers are still notoriously bad at semantics.
However, with a knowledge graph at hand, they can employ search via the navigation of parental and associative relations of entity ‘registered merchant’ in Coreon, and now the bot can infer that it is semantically close and connected to Founder (see below).

Homonymy & Terms Unseen By The Model
Another interesting use-case where a knowledge graph can help us is dealing with unseen terms and homonymy. If the user chooses to use slang or domain-specific terminology that was previously unknown to the model, SmartBot will first try to get its meaning using the connector to Coreon, not by taking a standard fallback at the first opportunity.
In the bot UI screenshot, the user enquires in German about the amount of money that can be received from the VBA. They refer to money as ‘Kohle’, which is a slang term that is also homonymous to ‘coal’, a fossil (think the analogy ‘dough’ in English).

Our training data did not contain this term, but the bot makes an API request and searches for it in the knowledge repository. There are two hits in the domain knowledge of the VBA: checking parent concepts and relations of both instances, we see that they belong to two distinct concepts.
The first instance belongs to the CO2 concept in the ‘smart city’ sub-tree, which hosts concepts related to resource-saving, renewable energy, and sustainability. And the second instance is found among synonyms for ‘financial means’ concept, which belongs to the concept denoting financial funds and has a more generic parent of ‘money’, a well-known instance in our NLU model.
Given the context of the conversation is corresponding, the meaning of ‘Kohle’ is disambiguated for the chatbot, and SmartBot informs the user about the amount of money they can qualify for.
Conclusion
To sum it all up: if you are considering developing a chatbot and are looking for ways to enhance its performance, try injecting a knowledge graph into it.
Aside from acquiring a resulting solution that is technically robust and easily scalable, you’d get a chance to reuse numerous open linked data resources. Your solution would profit from carefully structured knowledge that is sitting there waiting to be used.
The Coreon knowledge graph unlocks multilinguality, a super-power in the European context, and it also allows maintainers manage data consistently across languages, in a visual and user-friendly way. And of course, it reduces red tape, making business processes more rational and services more discoverable.
*Feature Image: Photo by Alex Knight from Pexels



